Computing |
|
Informatika |
The next generation of search

|
|
Nova generacija pretraživanja
|
A short history of web search
|
|
Kratka povijest pretraživanja weba
|
Into the deep
|
|
U dubinu
|
Real-time results
|
|
Rezultati u stvarnom vremenu
|
Some interesting statistics
|
|
Neke zanimljive statistike
|
Personalised search and voice search
|
|
Personalizirana pretraga i glasovna pretraga
|
Filling the websites with junk
|
|
Punjenje internetskih stranica smećem
|
The cyber crystal ball
|
|
Internetska kristalna kugla
|
|
|
|
|

The next generation of search
Back in 1990, before the web was born, Alan Emtage and his colleagues at McGill University in Montreal, Canada, designed a program to index software stored on the embryonic internet.
Archie, as Emtage named his program, was the first internet search engine.
Twenty years on and we call up a Google, Yahoo or Bing some 500,000 times every second.
They bring us the juiciest gossip, the best gifts and bargain holidays, and form the cornerstones of an economy worth trillions of dollars.
It is hard to imagine a world, real or virtual, without them.
To mark Archie's 20th birthday, we examine the wonders and woes of web search and asks whether it could work even better.
Google is synonymous with web search.
Some 60 per cent of users prefer it, performing roughly 2.4 billion searches every day.
All these clicks combined to earn the company a cool $6.5 billion profit last year.
But if you dream of muscling in on some of this fortune you should be aware of what you are letting yourself in for.
Building a search engine is like compiling a searchable index for a trillion-page book.
The index has to be contained on a limited number of servers, and each of its entries must be stored in such a way that the whole thing can be searched...
|
|
Nova generacija pretraživanja
Još davne 1990. godine, prije rođenja interneta, Alan Emtage i njegovi kolege na Sveučilištu McGill u Montrealu, Kanada, dizajnirali su program za indeksiranje računalnih programa pohranjenih na internetu koji je tada bio začetku.
Archie, kako je Emtage nazvao svoj program, bio je prva internetska tražilica.
Dvadeset godina kasnije internet se pretražuje pomoću Googlea, Yahooa ili Binga oko 500.000 puta svake sekunde.
Oni nam donose najsočnije tračeve, najbolje poklone i najpovoljnije godišnje odmore te čine temelj gospodarstva vrijednog trilijune dolara.
Bez njih je teško je zamisliti svijet, bio on stvaran ili virtualan.
Povodom Archiejevog 20. rođendana, razmatramo čuda i probleme pretraživanja interneta i ispitujemo bi li ono moglo funkcionirati još bolje.
Google je sinonim za pretraživanje interneta.
Preferira ga oko 60 posto korisnika, s oko 2,4 milijarde obavljenih pretraga svaki dan.
Svi ti klikovi zajedno zaradili su tvrtki 6,5 milijardi dolara dobiti prošle godine.
Međutim, ako maštate o tome da preotmete dio ovog bogatstva trebali biste biti svjesni u što se upuštate.
Stvaranje tražilice je poput sastavljanja indeksa za pretraživanje knjige od trilijun stranica.
Indeks mora biti sadržan na ograničenom broju servera, a svaki njegov unos mora biti pohranjen tako da se može pretražiti...
|

A short history of web search
1969 (October): ARPANET, the precursor to the internet, switched on
1990 (January): Alan Emtage and students a McGill University, Montreal, create Archie, the first internet search engine
1991 (August): Tim Berners-Lee creates specification for World Wide Web
1993 (November): Aliweb, the first web search engine, is announced
1994: Yahoo and Lycos launch
1995: AltaVista, Excite and Ask Jeeves launch
1996 (January): Larry Page and Sergey Brin collaborate on search engine called Backrub.
They would go on to found Google
1998 (September): Google opens for business and MSN launches
2000 (January): Chinese search engine Baidu launches
2000 (October): Google launches Adwords - sponsored links next to search results
2006 (January): Google launches Chinese search site that is subject to government censorship
2007 (May): European Commission investigates whether Google is breaking privacy rules by linking search data to individual users
2008 (January): Wikia Search is launched - a free and open-source search engine
2008 (July): Former Google staff launch search engine Cuil, dubbed the "Google Killer"
2008 (November): Google launches Google Flu Trends...
|
|
Kratka povijest pretraživanja weba
1969. godina (listopad): aktiviran ARPANET, preteča interneta
1990. godina (siječanj): Alan Emtage i studenti sa Sveučilišta McGill u Montrealu stvaraju Archie, prvu internetsku tražilicu
1991. godina (kolovoz): Tim Berners-Lee stvara specifikaciju za World Wide Web
1993. godina (studeni): najavljena prva internetska tražilica, Aliweb
1994. godina: pokrenuti Yahoo i Lycos
1995. godina: pokrenuti AltaVista, Excite i Ask Jeeves
1996. godina (siječanj): Larry Page i Sergey Brin surađuju na tražilici naziva Backrub.
Kasnije osnivaju Google
1998. godina (rujan): Google počinje s radom, a pokrenut je i MSN
2000. godina (siječanj): pokrenuta kineska tražilica Baidu
2000. godina (listopad): Google pokreće Adwords - sponzorirane linkove uz rezultate pretraživanja
2006. godina (siječanj): Google pokreće kinesku stranicu za pretraživanje koja je podložna državnoj cenzuri
2007. godina (svibanj): Europska komisija istražuje je li Google prekršio pravila o privatnosti povezujući pretraživanje podataka s pojedinim korisnicima
2008. godina (siječanj): pokrenut Wikia Search - besplatna tražilica otvorenog koda
2008. godina (srpanj): Bivši zaposlenici Googlea pokreću tražilicu Cuil, nazvanu "ubojica Googlea"
2008. godina (studeni): Google pokreće uslugu Google Flu Trends...
|

Into the deep
With billions of web pages in their indexes, you might imagine that if something is online, search engines will find it for you.
In reality, the vast majority of web pages are effectively invisible to them.
Some of this "deep web" contains isolated pages with few, if any, hyperlinks, making them difficult to index.
Much is stuff you wouldn't want to see anyway: web pages detailing old flight reservations, for example, or out-of-date product reviews on Amazon.
However, a large proportion are believed to contain openly accessible databases of everything from information on used cars to the prices of airline tickets.
Even ignoring password-protected and other private sites, the deep web is estimated to be at least 500 times the size of the "surface" web visible to search engines.
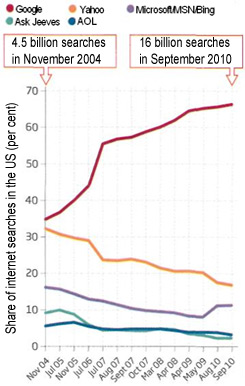
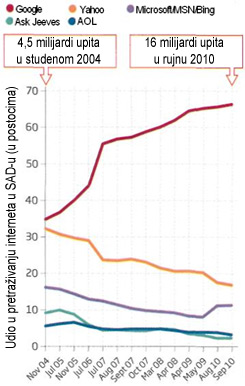
And by some estimates only 16 per cent of the surface web has been indexed by search engines - that is just 0.03 per cent of the whole (see Figure 1).

|
Figure 1: The yellow box is the surface web visible to search engines and the red are the websites indexed by search engines so far.
Juliana Freire at the University of Utah in Salt Lake City thinks that even this figure is...
|
|
U dubinu
Uz milijarde internetskih stranica u indeksima internetskih tražilica, mogli biste pomisliti da ako je nešto na internetu, tražilice će to pronaći za vas.
U stvarnosti, većina internetskih stranica je za njih u praksi nevidljiva.
Jedan dio tog "dubokog interneta" sadrži izolirane stranice s nekoliko, ako i toliko, hiperveza, što ih čini teškima za indeksiranje.
Tu ima i mnogo stvari koje ionako ne biste željeli vidjeti: internetskih stranica s pojedinostima o starim rezervacijama za put zrakoplovom, na primjer, ili zastarjele recenzije proizvoda na stranici Amazon.
Međutim, vjeruje se kako velik dio sadrži otvoreno dostupne baze podataka sa svime, od obavijesti o rabljenim automobilima do cijena zrakoplovnih karata.
Čak i ako ignoriramo stranice zaštićene lozinkom i druge privatne stranice, procjenjuje se da je duboki internet najmanje 500 puta veći od "površinskog" interneta vidljivog na tražilicama.
A po nekim procjenama, samo je 16 posto površinskog interneta indeksirano od strane tražilica - a to iznosi svega 0,03 posto u cjelini (pogledajte sliku 1).
|
|
Slika 1: Žuti pravokutnik predstavlja površinski internet vidljiv tražilicama, crveni predstavlja internetske stranice indeksirane od strane tražilica do sada.
Juliana Freire sa Sveučilišta Utah u Salt Lake Cityu smatra da je čak i ta brojka...
|

Real-time results
Few of us scan beyond the first 10 results turned up by a search engine, so it is a huge task to rank and present them in a way we can cope with.
"It's easy to overwhelm people with too much information," says Danny Sullivan, a web search expert at "Calafia Consulting" based in the UK.
What's more, billions of new pages are added to the web every day, and users expect search engines to be up to speed with 24-hour news feeds as well as the latest posts and status updates from sites such as Twitter and Facebook.
Yet web crawlers can take hours to work through the changes, meaning juicy scraps of gossip may be old news by the time a search engine tells you about them.
So search engines have had to up their game by delivering real-time results.
This takes more than just powerful computers and faster software.
Engineers are exploring strategies such as indexing the content of links and spotting newsworthy events through the sudden prevalence of posts transmitted from smartphones at specific locations or even the occurrence of certain terms (for example, "earthquake") in new content.
Then there is the need for a reputation system that gives priority to...
|
|
Rezultati u stvarnom vremenu
Malo nas pregledava više od prvih 10 rezultata koje izbaci tražilica, tako da je ogroman posao poredati ih i predstaviti na način na koji se možemo nositi s njima.
"Ljude se bez problema može zatrpati prevelikom količinom podataka", kaže Danny Sullivan, stručnjak za internetsko pretraživanje u tvrtki "Calafia Consulting" sa sjedištem u Ujedinjenom Kraljevstvu.
Osim toga, na internet se svaki dan dodaju milijarde novih stranica, a korisnici od tražilica očekuju da budu u toku s novostima 24 sata, kao i s najnovijim postovima i ažuriranim statusima sa stranica kao što su Twitter i Facebook.
No pretraživači mogu satima obrađivati izmjene, što znači da će sočni tračevi biti stara vijest kad vas tražilica o njima obavijesti.
Stoga su tražilice morale poboljšati svoju učinkovitost dajući rezultate u stvarnom vremenu.
To ne zahtijeva samo moćna računala i brže računalne programe.
Inženjeri istražuju strategije poput indeksiranja sadržaja poveznica i uočavanja događaja vrijednih pažnje u sve češćim postovima poslanima s pametnih telefona na određenim mjestima ili čak javljanje određenih izraza (kao što je "potres") u novom sadržaju.
Isto tako, postoji potreba za sustavom reputacije koji daje prvenstvo...
|

Some interesting statistics
Chart 1: The rise of Google in the US
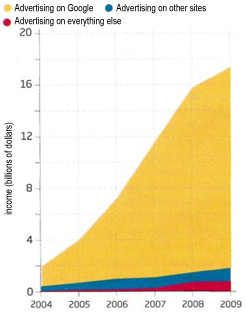
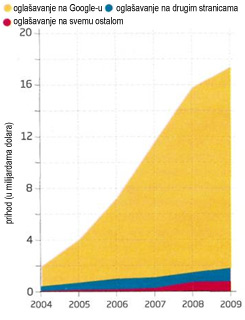
Chart 2: Adverts on Google's search results page now account for about 90 per cent of the company's income.
The past two years have seen a steady increase in the average length of search queries as people seek more precise results.
The average number of words used for a web search in July 2008 was 2.9.
In June 2010...
|
|
Neke zanimljive statistike
Grafikon 1: Uspon Googlea u SAD-u
Grafikon 2: Oglasi na Googleovoj stranici s rezultatima pretraživanja trenutno imaju udio od oko 90 posto u prihodima tvrtke.
U posljednje dvije godine postojao je stalan porast prosječne duljine upita za pretraživanje kako ljudi traže sve preciznije rezultate.
Prosječan broj riječi koji se koristio za pretraživanje interneta u srpnju 2008. godine bio je 2,9.
U lipnju 2010...
|

Personalised search and voice search
We are used to seeing sponsored links, paid for by advertisers, alongside our search results.
These are targeted: search engines keep track of the most popular links associated with every search term and display these accordingly.
Google can also keep track of your web search history to provide results it thinks you will like.
Now Bing has gone one step further by personalising search results based on the likes of your Facebook friends.
Eventually, according to Google CEO Eric Schmidt, given your web search history, your location plus a few other details, a search engine will be able to decide for itself what information to give you.
You won't even need to type in a query.Also, a quarter of web searches made from cellphones equipped with Google's Android software rely on voice input.
Every search helps refine the underlying speech recognition database, improving performance in noisy conditions, such as on the train, and its ability to handle...
|
|
Personalizirana pretraga i glasovna pretraga
Mi smo navikli gledati sponzorirane linkove, za koje plaćaju oglašivači, uz naše rezultate pretraživanja.
Oni su ciljani: tražilice prate najpopularnije linkove povezane uz svaki pojam za pretraživanje i u skladu s tim ih prikazuju.
Google također može pratiti vašu povijest pretraživanja interneta kako bi dao rezultate za koje smatra da će vam se svidjeti.
Sada je Bing otišao i korak dalje, personalizacijom rezultata pretraživanja na temelju onog što se sviđa vašim prijateljima s Facebooka.
Prema Googleovom izvršnom direktoru Ericu Schmidtu, jednog dana, a s obzirom na vašu povijest pretraživanja interneta, vašu lokaciju i nekoliko drugih detalja, tražilice će moći odlučiti kakve će vam informacije dati.
Čak nećete morati niti utipkati upit.Također, četvrtina pretraživanja interneta koja dolazi od mobitela opremljenih Googleovim Android softverom oslanja se na glasovni unos podataka.
Svaka pretraga pomaže u poboljšanju temeljne baze podataka prepoznavanja govora, poboljšavajući performanse u bučnim uvjetima, na primjer u vlaku, te njenu sposobnost da obrađuje...
|

Filling the websites with junk
"Search engines are the sunlight of the web, showing us what is visible," says Kevin Chang, a computer scientist at the University of Illinois.
But by their nature, he adds, the beams that guide us also cast deep shadows.
Chang is referring to the huge power that search engines wield.
With online commerce worth $34 billion a year in the US alone, any bias for or against a company in search results can have a huge effect.
Some studies suggest that search engines reinforce inequalities in the online world by giving websites that are already popular a high ranking in results, thus making them even more popular.
Other studies contradict this, indicating that search engines also boost less popular sites.
Whatever the truth, with so much potential business at stake it is hardly surprising that website owners "tweak" their sites to try to ensure they always float to the top of the rankings.
Some even resort to tricks such as overstuffing web pages with keywords...
|
|
Punjenje internetskih stranica smećem
"Tražilice su sunčeva svjetlost interneta, pokazuju nam ono što je vidljivo," kaže Kevin Chang, računalni znanstvenik sa Sveučilišta u Illinoisu.
No, po svojoj prirodi, dodaje on, zrake koje nas vode također bacaju i tamne sjene.
Chang ukazuje na na veliku moć koju imaju tražilice.
Uz internetsku trgovinu vrijednu 34 milijarde dolara godišnje samo u SAD, bilo kakva pristranost ili nepristranost nekoj tvrtki u rezultatima pretraživanja može imati veliki utjecaj.
Neke studije sugeriraju da tražilice pojačavaju nejednakosti u internetskom svijetu dajući stranicama koje su već popularne visoku poziciju među rezultatima, što ih čini još popularnijima.
Druge studije se ne slažu, naglašavajući kako tražilice također uzdižu i manje popularne stranice.
Kakva god bila istina, uz toliko potencijalnog posla na kocki ne čudi da vlasnici internetskih stranica "podešavaju" svoje stranice kako bi pokušali osigurati da one stalno plutaju na vrhu ljestvice rezultata.
Neki čak pribjegavaju trikovima poput pretjeranog punjenja stranica ključnim riječima...
|

The cyber crystal ball
Web search holds the key to the future.
A group that runs the "Web Bot" project uses web crawler software to find 300,000 keywords in blogs and forums, then applies a filtering algorithm to the text around each keyword, combining the results to predict future events.
So far the results of this "wisdom of crowds" approach have been mixed.
Yet in May, Google saw fit to invest in "Recorded Future", a Boston-based start-up that specialises in novel ways to relate the past, present and future.
Its software collates web-based information about people, places and events, as well as news reports and posts from blogs and social media sites.
Specialised algorithms then label the information, look for connections and attempt to plot the "online momentum" for each event.
According to Recorded Future, this can help predict events such as stock market trends, the launch of new pharmaceuticals, even terrorist attacks.
Yahoo's research lab in Barcelona, Spain, has developed a similar system called "Time Explorer".
Yet search queries themselves could prove...
|
|
Internetska kristalna kugla
Pretraživanje interneta drži ključ budućnosti.
Skupina koja vodi projekt "Web Bot" koristi softver za automatsko izvlačenje informacija s interneta kako bi pronašla 300.000 ključnih riječi u blogovima i forumima, a zatim primjenjuje algoritam za filtriranje teksta oko svake ključne riječi, kombinirajući rezultate kako bi predvidjela buduće događaje.
Do sada su rezultati ovog pristupa "mudrosti mnoštva" mješoviti.
Ipak, u svibnju, Google je smatrao prikladnom investiciju u "Recorded Future", novoosnovano poduzeće sa sjedištem u Bostonu koje se specijaliziralo za nove načine povezivanja prošlosti, sadašnjosti i budućnosti.
Njezin softver sjedinjuje informacije s interneta o ljudima, mjestima i događajima, kao i vijesti i članke s blogova i stranica o društvenim medijima.
Specijalizirani algoritmi zatim označavaju informacije, traže poveznice i pokušavaju prikazati "internetski zamah" za svaki događaj.
Prema tvrtki Recorded Future, to može pomoći predvidjeti događaje poput kretanja na burzi, lansiranja novih farmaceutskih proizvoda, čak i terorističkih napada.
Yahooov istraživački laboratorij u Barceloni, Španjolska, razvio je sličan sustav pod nazivom "Time Explorer".
Pa ipak, pretraživački upiti bi se sami po sebi mogli pokazati...
|
|
|